A Play on Regular Expression
The paper where the algorithms we described in the recent blog posts come from is now available. It is written as a play in three Acts with a cast of three and is very readable and funny. The Haskell code is at Sebastian Fischer's github pages.
EuroPython 2010 report
So, EuroPython 2010 is over, I am flying home and it's time to write a report about the conference from the PyPy point of view.
As usual, the conference was very interesting and went very well. The quality of the talks I attended to was high on average and most importantly I could meet a lot of interesting people to discuss various things.
On the first day, Armin, Amaury and I presented the usual PyPy status talk (here are the slides): the talk is an extended version of the one that I and Armin presented at Pycon Italia in May and is divided in three parts: first I talked about the current status of the project, what is the content of the recent 1.2 and 1.3 releases and showed a demo of a simple Django application that renders a Mandelbrot fractal and is measurably faster on PyPy than on CPython. In the second part of the talk, Armin gave an introduction about the ideas that stand behind the JIT. Finally, in the third part Amaury explained how the new cpyext module lets PyPy to compile and load existing CPython extensions written in C.
I think that the talk was well received: the only drawback is that there was no time to answer questions at the end of the presentation. However, we received a lot of "offline" questions after the talk finished and thorough the whole conference: it is always great to see that people are interested in our work, and I'd like to thank everybody for the feedback that they gave to us.
PyPy was also mentioned in the interesting Mark Shannon's talk, where he compared the optimization techniques used by PyPy, Unladen Swallow and HotPy, which is Mark's own PhD project. Moreover, Henrik Vendelbo gave a talk about how to tweak PyPy to produce a standalone executable which embeds a whole python application to make deployment easier, while Andrew Francis explained his implementation of the Go select statement based on the stackless.py module implemented in PyPy. Personally, I am glad to see that people start to think of PyPy as a useful starting point to experiment with new features and use cases that we did not think about: after all, one of PyPy explicit goals is to be "flexible and easy to experiment with".
After the conference there were the usual post EuroPython sprints: this year we had not planned a PyPy sprint, but some people showed interest in it and since Armin and I happened to be still around the day after the conference, we decided to do a mini 1-day sprint, with 6 or 7 people present. Since there were only two core developers it was impossible to use our usual pairing scheme, in which every newcomer pairs with someone who is experienced with the source code to gain knowledge of it. However, I think it was still a successful day of work, and we managed to fix a couple of bugs that was standing in our issue tracker. Again, I'd like to thank all the people that came and worked with us during the sprint.
In conclusion I really enjoyed the EuroPython 2010 experience: the fact that I managed to find a place in Birmingham where to eat a good Italian-style "gelato" helped a lot :-).
CERN Sprint Report – Wrapping C++ Libraries
The last five days we have been sprinting in a meeting room in the Computing Center at CERN in Genève, Switzerland. Present are Armin Rigo, Antonio Cuni, Carl Friedrich Bolz and Wim Lavrijsen (LBL). The goal of the sprint was to use some of the C++ technology developed at CERN to make it possible to use C++ libraries from PyPy's Python interpreter. For this we used the Reflex library, which provides reflection information for C++ classes. We discussed using Reflex in PyPy during the Düsseldorf sprint of 2008, please read that blog post if you want some more details on how Reflex works. There is support for this sort of C++/Python integration also for CPython, using the PyROOT module.
The sprint was very successful. On Monday we had a few discussion about how Reflex could best be integrated with PyPy. One of the goals of the sprint was to make the approach JIT-friendly from the start, so that calls to C++ libraries can be reasonably fast. After the discussion we started coding on the reflex-support branch. This branch adds a new cppyy builtin module to PyPy's Python interpreter (why we chose that name is left as an exercise to the reader). This module can be used to load C++ classes, construct instances and call static and instance methods on them.
The work has just started, as of now, the argument and return types of the methods are restricted to some simple C types, such as int, double and char* and pointers to class instances. Most of the work necessary to properly resolve overloaded methods is done, but default arguments are not.
As an example, suppose there is a C++ class like this:
class example01 {
private:
static int count;
int somedata;
public:
example01(int a) : somedata(a) {
count++;
}
~example01() {
count--;
}
static int getCount() {
return count;
}
int addDataToInt(int a) {
return somedata + a;
}
};
int example01::count = 0;
You can now use it from PyPy's Python interpreter in the following way, after you have used Reflex to generate reflection information for the class:
import cppyy
cppyy.load_lib("example01Dict.so") # contains the Reflex information
example01_class = cppyy.gbl.example01
instance = example01_class(7)
assert example01_class.getCount() == 1
res = instance.addDataToInt(4)
assert res == 11
res = instance.addDataToInt(-4)
assert res == 3
instance.destruct() # so far explicit destruction needed
assert example01_class.getCount() == 0
We also did some very early JIT work and some early performance measurements. The rough figures are that cppyy is two times faster at calling a simple C++ method from Python than PyROOT. To get a feeling for how fast things could go in the end, we also implemented a proof-of-concept for some more advanced JIT technology (which requires a patch for Reflex and uses a GCC extension). With this, the speedup over PyROOT is a factor of 20. Of course, this is still a lot slower than a C++ to C++ method call (probably by at least an order of magnitude).
The sprint was very productive because we managed to get the right people into the same room working together. Wim has a lot of experience with C++ and Reflex, and is the author of PyROOT, and of course the others know a lot about PyPy (at the end of the sprint, Anto was very glad that he stopped using C++ a long time ago). Also, working at CERN was very cool. The atmosphere is amazing, and we got to visit the ATLAS control room. Extremely advanced technology, and also research on a completely different scale than what we are used to.
Comparing SPUR to PyPy
Recently, I've become aware of the SPUR project of Microsoft Research and read some of their papers (the tech report "SPUR: A Trace-Based JIT Compiler for CIL" is very cool). I found the project to be very interesting and since their approach is in many ways related to what PyPy is doing, I now want to compare and contrast the two projects.
A Tracing JIT for .NET
SPUR consist of two parts: On the one hand it is a VM for CIL, the bytecode of the .NET VM. This VM uses a tracing JIT compiler to compile the programs it is running to machine code. As opposed to most existing VMs that have a tracing JIT it does not use an interpreter at all. Instead it contains various variants of a JIT compiler that produce different versions of each method. Those are:
- a profiling JIT which produces code that does lightweight profiling when running the compiled method
- a tracing JIT which produces code that produces a trace when running the compiled method
- a transfer-tail JIT which is used to produce code which is run to get from a failing guard back to the normal profiling version of a method
- an optimizing JIT that actually optimizes traces and turns them into machine code
Optimizations Done by the Optimizing JIT
SPUR's optimizing JIT does a number of powerful optimizations on the traces before it turns them into machine code. Among them are usual compiler optimizations such as register allocation, common subexpression elimination, loop invariant code motion, etc.
It also performs some optimizations that are specific to the tracing context and are thus not commonly found in "normal" compilers:
- guard implication: if a guard is implied by an earlier guard, it is removed
- guard strengthening: if there is a sequence of guards that become stronger and stronger (i.e. each guard implies the previous one), the first guard in the sequence is replaced by the last one, and all others are removed. This can greatly reduce the number of guards and is generally safe. It can shift a guard failure to an earlier point in the trace, but the failure would have occurred at some point in the trace anyway.
- load/store optimizations: this is an optimization for memory reads/writes. If several loads from the same memory location occur without writes in between, all but the first one are removed. Similarly, if a write to a memory location is performed, this write is delayed as much as possible. If there is a write to the same location soon afterwards, the first write can be removed.
- escape analysis: for allocations that occur in a loop, the optimizer checks whether the resulting object escapes the loop. If not, the allocation is moved before the loop, so that only one object needs to be allocated, instead of one every loop iteration.
- user-controlled loop unrolling: not exactly an optimization, but an interesting feature anyway. It is possible to annotate a CIL method with a special decorator [TraceUnfold] and then the tracing JIT will fully unroll the loops it contains. This can be useful for loops than are known to run a small and fixed number of iterations for each call-site.
- user controlled tracing: The user can also control tracing up to a point. Methods can be annotated with [NativeCall] to tell the tracer to never trace their execution. Instead they appear as a direct call in the trace.
A JavaScript Implementation
In addition to the tracing JIT I just described, SPUR also contains a JavaScript implementation for .NET. The approach of this implementation is to translate JavaScript to CIL bytecode, doing some amount of type inference to detect variables that have fixed types. All operations where no precise type could be determined are implemented with calls to a JavaScript runtime system, which does the necessary type dispatching. The JavaScript runtime is implemented in C#.
The JavaScript implementation and the CLI VM with a tracing JIT sound quite unrelated at first, but together they amplify each other. The tracing JIT traces the JavaScript functions that have been translated to CLI bytecode. Since the JavaScript runtime is in C#, it exists as CLI bytecode too. Thus it can be inlined into the JavaScript functions by the tracer. This is highly beneficial, since it exposes the runtime type dispatching of the JavaScript operations to the optimizations of the tracing JIT. Particularly the common expression elimination helps the JavaScript code. If a series of operations is performed on the same object, the operations will all do the same type checks. All but the type checks of the first operation can be removed by the optimizer.
Performance Results
The speed results of the combined JavaScript implementation and tracing JIT are quite impressive. It beats TraceMonkey for most benchmarks in SunSpider (apart from some string-heavy benchmarks that are quite slow) and can compete with V8 in many of them. However, all this is steady-state performance and it seems SPUR's compile time is rather bad currently.
Further Possibilities
A further (so far still hypothetical) advantage of SPUR is that the approach can optimize cases where execution crosses the border of two different systems. If somebody wrote an HTML layout engine and a DOM in C# to get a web browser and integrated it with the JavaScript implementation described above, the tracing JIT could optimize DOM manipulations performed by JavaScript code as well as callbacks from the browser into JavaScript code.
Of course the approach SPUR takes to implement JavaScript is completely generalizable. It should be possible to implement other dynamic languages in the same way as JavaScript using SPUR. One would have to write a runtime system for the language in C#, as well as a compiler from the language into CIL bytecode. Given these two elements, SPUR's tracing JIT compiler would probably do a reasonable job at optimizing this other language (of course in practise, the language implementation would need some tweaking and annotations to make it really fast).
Comparison With PyPy
The goals of PyPy and SPUR are very similar. Both projects want to implement dynamic languages in an efficient way by using a tracing JIT. Both apply the tracing JIT "one level down", i.e. the runtime system of the dynamic language is visible to the tracing JIT. This is the crucial point of the approach of both projects. Since the runtime system of the dynamic language is visible to the tracing JIT, the JIT can optimize programs in that dynamic language. It does not itself need to know about the semantics of the dynamic language. This makes the tracing JIT usable for a variety of dynamic languages. It also means that the two halves can be implemented and debugged independently.
In SPUR, C# (or another language that is compilable to CIL) plays the role of RPython, and CIL is equivalent to the intermediate format that PyPy's translation toolchain uses. Both formats operate on a similar abstraction level, they are quite close to C, but still have support for the object system of their respective language and are garbage-collected.
SPUR supports only a JavaScript implementation so far, which could maybe change in the future. Thus JavaScript in SPUR corresponds to Python in PyPy, which was the first dynamic language implemented in PyPy (and is also the reason for PyPy's existence).
There are obviously also differences between the two projects, although many of them are only skin-deep. The largest difference is the reliance of SPUR on compilers on all levels. PyPy takes the opposite approach of using interpreters almost everywhere. The parts of PyPy that correspond to SPUR's compilers are (I will use the Python implementation of PyPy as an example):
- the JavaScript-to-CIL compiler corresponds to the Python interpreter of PyPy
- the profiling JIT corresponds to a part of PyPy's translation toolchain which adds some profiling support in the process of turning RPython code into C code,
- the tracing JIT corresponds to a special interpreter in the PyPy JIT which executes an RPython program and produces a trace of the execution
- the transfer-tail JIT corresponds to PyPy's blackhole interpreter, also called fallback interpreter
- the optimizing JIT corresponds to the optimizers and backends of PyPy's JIT
PyPy's Optimizations
Comparing the optimizations that the two projects perform, the biggest difference is that PyPy does "trace stitching" instead of fully supporting trace trees. The difference between the two concerns what happens when a new trace gets added to an existing loop. The new trace starts from a guard in the existing loop that was observed to fail often. Trace stitching means that the loop is just patched with a jump to the new trace. SPUR instead recompiles the whole trace tree, which gives the optimizers more opportunities, but also makes compilation a lot slower. Another difference is that PyPy does not perform loop-invariant code motion yet.
Many of the remaining optimizations are very similar. PyPy supports guard implication as well as guard strengthening. It has some load/store optimizations, but PyPy's alias analysis is quite rudimentary. On the other hand, PyPy's escape analysis is very powerful. PyPy also has support for the annotations that SPUR supports, using some decorators in the pypy.rlib.jit module. User-controlled loop unrolling is performed using the unroll_safe decorator, tracing of a function can be disabled with the dont_look_inside decorator.
PyPy has a few more annotations that were not mentioned in the SPUR tech report. Most importantly, it is possible to declare a function as pure, using the purefunction decorator. PyPy's optimizers will remove calls to a function decorated that way if the arguments to the call are all constant. In addition it is possible to declare instances of classes to be immutable, which means that field accesses on constant instances can be folded away. Furthermore there is the promote hint, which is spelled x = hint(x, promote=True). This will produce a guard in the trace, to turn x into a constant after the guard.
Summary
Given the similarity between the projects' goals, it is perhaps not so surprising to see that PyPy and SPUR have co-evolved and reached many similar design decisions. It is still very good to see another project that does many things in the same way as PyPy.
Besides being similar projects, is it possible to cross the streams? Could PyPy's CLI backend take the place of the JavaScript-to-CIL compiler (or is that the wrong parallel)?
@Anonymous: I guess you could program stuff in RPython, compile to CIL and get it jitted by SPUR. However, this wouldn't work well for our main RPython programs, which are all interpreters. Using a tracing JIT on an interpreter without doing anything special is not helping much.
"Blackhole" interpreter
Hi all,
Here are a few words about the JIT's "great speedup in compiling time" advertized on the PyPy 1.3 release (see the previous blog post). The exact meaning behind these words needs a fair bit of explanation, so here it is in case you are interested.
If you download a version of PyPy 1.3 that includes a JIT compiler, you get an executable that could be qualified as rather fat: it actually contains three interpreters. You have on the one hand the regular Python interpreter. It is here because it's not possible to JIT-compile every single piece of Python code you try to run; only the most executed loops are JIT-compiled. They are JIT-compiled with a tracing interpreter that operates one level down. This is the second interpreter. This tracing step is quite slow, but it's all right because it's only invoked on the most executed loops (on the order of 100 to 1000 times in total in a run of a Python script that takes anyway seconds or minutes to run).
So apart from the JIT compilation itself, we have two worlds in which the execution proceeds: either by regular interpretation, or by the execution of assembler code generated by the JIT compiler. And of course, we need to be able to switch from one world to the other quickly: during regular interpretation we have to detect if we already have generated assembler for this piece of code and if so, jump to it; and during execution of the assembler, when a "guard" fails, i.e. when we meet a path of execution for which we did not produce assembler, then we need to switch back to regular interpretation (or occasionally invoke the JIT compiler again).
Let us consider the cost of switching from one world to another. During regular interpretation, if we detect that we already have assembler corresponding to this Python loop, then we just jump to it instead of interpreting the Python loop. This is fairly cheap, as it involves just one fast extra check per Python loop. The reverse is harder because "guard" failures can occur at any point in time: it is possible that the bit of assembler that we already executed so far corresponds to running the first 4 Python opcodes of the loop and a half. The guard that failed just now is somewhere in the middle of interpreting that opcode -- say, multiplying these two Python objects.
It's almost impossible to just "jump" at the right place in the code of the regular interpreter -- how do you jump inside a regular function compiled in C, itself in a call chain, resuming execution of the function from somewhere in the middle?
So here is the important new bit in PyPy 1.3. Previously, what we would do is invoke the JIT compiler again in order to follow what needs to happen between the guard failure and the real end of the Python opcode. We would then throw away the trace generated, as the only purpose was to finish running the current opcode. We call this "blackhole interpretation". After the end of the Python opcode, we can jump to the regular interpreter easily.
Doing so was straightforward, but slow, in case it needs to be done very often (as in the case in some examples, but not all). In PyPy 1.3, this blackhole interpretation step has been redesigned as a time-critical component, and that's where the third interpreter comes from. It is an interpreter that works like the JIT compiler, but without the overhead of tracing (e.g. it does not need to box all values). It was designed from the ground up for the sole purpose of finishing the execution of the current Python opcode. The bytecode format that it interprets is also new, designed for that purpose, and the JIT compiler itself (the second interpreter) was adapted to it. The old bytecode format in PyPy 1.2 is gone (it was more suited for the JIT compiler, but less for blackhole interpretation).
In summary, it was a lot of changes in the most front-end-ish parts of the JIT compiler, even though it was mostly hidden changes. I hope that this longish blog post helped bring it a bit more to the light :-)
Interesting, is there any documentation for the different bytecode sets you have/had?
I would be especially interested in the differences, and the reasons for those design decisions.
I fear not. The bytecode set is quite custom, made to represent RPython code, which is at the level (roughly speaking) of Java -- with a few additional instructions to guide the JIT compiler. The latest version uses a register-based machine, which is more convenient than a Java-like stack-based approach starting from the control flow graphs of RPython functions. It has three independent sets of registers: integers, pointers, and floating-point (pointers are different from integers at this level because the GC needs to track them and possibly move them). Register numbers are encoded in one byte, so there is room for 256 registers of each kind, but in practice doing a simple register allocation step on each graph means that no bytecode ends up using more than ~15 registers. A few parts are needed only by the JIT compiler and not by the blackhole interpreter; these are encoded "off-line" to avoid slowing down the blackhole interpreter.
Well, I could talk at length about all the details of the format, but in truth there is nothing very deep there :-) See the comments in https://codespeak.net/svn/pypy/trunk/pypy/jit/codewriter/codewriter.py as well as the tests like test/test_flatten.py and test/test_regalloc.py.
Does the PyPy JIT replace a running interpreted loop with a compiled one mid-run or only on the next iteration or only the next time this loop starts?
Is there a way to ask the PyPy interpreter to tell me what it jitted as it ran some code?
Or will it be too difficult for me to relate the produced machine code with my python source code (because it's not a straightforward method jit)?
Hi Zeev.
Only at the next iteration of the loop. However, you have to have at least ~1000 iterations before it happens.
There is a variety of tools that we use for inspecting generated loops. There is no programmable interface from python yet, but there are some external tools.
Run: PYPYJITLOG=jit-log-opt:log pypy
and you'll get a file log which contains all the loops. There are tools in the source checkout pypy/jit/tool, loopviewer.py, showstats.py and traceviewer.py which can help you viewing those loops. They'll contain debug_merge_points which are with info about python opcodes (including functions and file), but they can span several functions. Have fun :)
If you want more info, drop by on #pypy at irc.freenode.net.
Cheers,
fijal
@Luis: just to expand a bit Armin's answer :-).
Jaegermonkey is a method-by-method compiler that Tracemonkey uses *before* the tracing compiler enters in action. In pypy, this is equivalent to the normal Python interpreter that profiles your loops to find the hot ones, with the obvious difference that Jaegermonkey is a compiler, while ours is an interpreter.
The blackhole interpreter is something that it's used internally by our tracing jit compiler, and AFAIK it has no equivalent in tracemonkey.
PyPy 1.3 released
Hello.
We're please to announce the release of PyPy 1.3. This release has two major improvements. First of all, we stabilized the JIT compiler since 1.2 release, answered user issues, fixed bugs, and generally improved speed.
We're also pleased to announce alpha support for loading CPython extension modules written in C. While the main purpose of this release is increased stability, this feature is in alpha stage and it is not yet suited for production environments.
Highlights of this release
-
We introduced support for CPython extension modules written in C. As of now, this support is in alpha, and it's very unlikely unaltered C extensions will work out of the box, due to missing functions or refcounting details. The support is disabled by default, so you have to do:
import cpyext
before trying to import any .so file. Also, libraries are source-compatible and not binary-compatible. That means you need to recompile binaries, using for example:
pypy setup.py build
Details may vary, depending on your build system. Make sure you include the above line at the beginning of setup.py or put it in your PYTHONSTARTUP.
This is alpha feature. It'll likely segfault. You have been warned!
-
JIT bugfixes. A lot of bugs reported for the JIT have been fixed, and its stability greatly improved since 1.2 release.
-
Various small improvements have been added to the JIT code, as well as a great speedup of compiling time.
Cheers,
Maciej Fijalkowski, Armin Rigo, Alex Gaynor, Amaury Forgeot d'Arc and the PyPy team
Update:The correct command to build extension is "pypy setup.py build", not "python setup.py build" as it was stated before.
fyi benchmarks game
A JIT for Regular Expression Matching
This is part 2 of a series, see Part 1 for an introduction. In this post I want to describe how the JIT generator of the PyPy project can be used to turn the elegant but not particularly fast regular expression matcher from the first part into a rather fast implementation. In addition, I will show some speed measurements against various regular expression implementations.
Again, note the disclaimer: This technology could not easily be used to implement Python's re-module.
Example Expression and First Numbers
The regular expression I will use as an example in the rest of this paper is the expression (a|b)*a(a|b){20}a(a|b)*. It matches all strings that have two a with exactly 20 characters between them. This regular expression has the property that the corresponding DFA needs 2**(n+1) different states. As an input string, we use a random string (of varying lengths) that does not match the regular expression. I will give all results as number of chars matched per second. While this is not a particularly typical regular expression, it should still be possible to get some ballpark numbers for the speeds of various implementations – as we will see, the differences between implementations are huge anyway.
All the benchmarks were performed on my laptop, which has an Intel Core2 Duo P8400 processor with 2.26 GHz and 3072 KB of cache on a machine with 3GB RAM running Ubuntu Linux 10.04.
To get a feeling for the orders of magnitude involved, the CPython re module (which is implemented in C and quite optimized) can match 2'500'000 chars/s. Google's new re2 implementation still matches 550'000 chars/s. Google's implementation is slower, but their algorithm gives complexity and space guarantees similar to our implementation in the last blog post.
On the other end of the performance scale is the pure-Python code from the last blog post running on CPython. It can match only 12'200 chars/s and is thus 200 times slower than the re module.
Translating the Matcher
The code described in the last blog post is not only normal Python code, but also perfectly valid RPython code. Nothing particularly dynamic is going on in the code, thus it can be translated with PyPy's translation toolchain to C code. The resulting binary is considerably faster and can match 720'000 chars/s, 60 times faster than the untranslated version.
Another approach is to write equivalent versions of the algorithms in lower level languages. This has been done for C++ by Sebastian Fischer and for Java by Baltasar Trancón y Widemann. The algorithm is object-oriented enough to be mapped very closely to the respective languages. The C++ version is a little bit faster than the RPython version translated to C, at 750'000 chars/s. That's not very surprising, given their similarity. The Java version is more than twice as fast, with 1'920'000 chars/s. Apparently the Java JIT compiler is a lot better at optimizing the method calls in the algorithm or does some other optimizations. One reason for this could be that the Java JIT can assume that the classes it sees are all there are (and it will invalidate the generated machine code if more classes are loaded), whereas the C++ compiler needs to generate code that works even in the presence of more regular expression classes.
Generating a JIT
To get even more performance out of the RPython code, it is possible to generate a JIT for it with the help of the PyPy translation toolchain. To do this, the matching code needs to be extended somewhat by some hints that tell PyPy's JIT generator how this is to be done. The JIT generator can automatically produce a JIT compiler from an RPython interpreter of the source language. In our case, we view the regular expression matcher as an interpreter for regular expressions. Then the match function corresponds to the dispatch loop of a traditional interpreter.
Our regular expression matcher is a very peculiar interpreter. The matcher works by running exactly one loop (the one in match) as many times as the input string is long, irrespective of the "program", i.e. the particular regular expressions. In addition, within the loop there are no conditions (e.g. if statements) at all, it is just linear code. This makes it almost perfectly suited to the JIT generator, which produces a tracing JIT. A tracing JIT compiles the hot loops of a program (i.e. regular expression) and has to do extra work if there are conditions in the loop. In our case, there is exactly one loop per regular expression, without any condition.
JIT Hints
The hints that are needed for the match function of the last blog post can be seen here (the function is slightly rewritten, e.g. the JIT does only properly support a while loop as the main dispatch loop):
jitdriver = jit.JitDriver(reds=["i", "result", "s"], greens=["re"])
def match(re, s):
if not s:
return re.empty
# shift a mark in from the left
result = re.shift(s[0], 1)
i = 1
while i < len(s):
jitdriver.can_enter_jit(i=i, result=result, s=s, re=re)
jitdriver.jit_merge_point(i=i, result=result, s=s, re=re)
# shift the internal marks around
result = re.shift(s[i], 0)
i += 1
re.reset()
return result
The jitdriver is an instance describing the data of the interpreter we are dealing with. The arguments to the constructor need to list all local variables of the dispatch loop. The local variables are classified into two classes, red ones and green ones. The green ones hold the objects that make up the program that the interpreter currently runs and which position in the program is currently being executed. In a typical bytecode interpreter, the bytecode object and the program counter would be green. In our case, the regular expression is the program, so it is green. The rest of the variables are red.
The green variables are treated specially by the JIT generator. At runtime, for a given value of the green variables, one piece of machine code will be generated. This piece of machine code can therefore assume that the value of the green variable is constant.
There are two additional hints, which are method calls on the jitdriver instance. The jit_merge_point method marks the beginning of the main interpreter loop. The can_enter_jit function marks the point where a loop in the user program can be closed, which in our case is trivial, it's just at the end of the interpreter loop (for technical reasons it is put at the beginning, because nothing must happen between the can_enter_jit and jit_merge_point invocations).
Those are the hints that the JIT generator needs to function at all. We added some additional hints, that give the JIT generator more information to work with. Those hints are immutability information, which means that certain instance fields can not be changed after the object has been constructed. Apart from the marked field, none of the fields of any of the Regex subclasses can change. For example for the Char class this is expressed in the following way:
class Char(Regex):
_immutable_fields_ = ["c"]
def __init__(self, c):
...
These hints allow the generated JIT to constant-fold reads out of the immutable fields in some situations.
Adaptions to the Original Code
In the introduction above I wrote that the code within the loop in match uses no conditions. It is indeed true that none of the _shift methods have an if statement or similar. However, there are some hidden conditions due to the fact that the and and or boolean operators are used, which are short-circuiting. Therefore the JIT-version of the code needs to be adapted to use the non-short-circuiting operators & and |.
JIT Example
To get an impression of how the generated machine code looks like, consider the regular expression (a|b)*. As regular expression objects this would be Repetition(Alternative(Char('a'), Char('b'))). The machine code in its intermediate, machine-independent form looks as follows (I have slightly cleaned it up and added comments for clarity):
# arguments of the loop
# i0 is i in the match function
# result0 is result in the match function
# s0 is s in the match function
[i0, result0, s0] # those are the arguments to the machine code
char = s0[i0] # read the character
# read the current mark:
i5 = ConstPtr(ptr_repetition).marked
i7 = char == 'a' # is the character equal to 'a'
i8 = i5 & i7
i10 = char == 'b' # is the character equal to 'b'
i11 = i5 & i10
# write new mark
ConstPtr(ptr_chara).marked = i8
i13 = i8 | i11
# write new mark
ConstPtr(ptr_charb).marked = i11
# write new mark
ConstPtr(ptr_alternative).marked = i13
# increment the index
i17 = i0 + 1
i18 = len(s0)
# write new mark
ConstPtr(ptr_repetition).marked = i13
# check that index is smaller than the length of the string
i19 = i17 < i18
if not i19:
go back to normally running match
jump(i17, i13, s0) # start from the top again
The various ConstPtr(ptr_*) denote constant addresses of parts of the regular expression tree:
- ptr_repetition is the Repetition
- ptr_chara is Char('a')
- ptr_charb is Char('b')
- ptr_alternative is the Alternative
Essentially the machine code reads the next char out of the string, the current mark out of the Repetition and then performs some boolean operations on those, writing back the new marks. Note in particular how the generated machine code does not need to do any method calls to shift and _shift and that most field reads out of the regular expression classes have been optimized away, because the fields are immutable. Therefore the machine code does not need to deconstruct the tree of regular expression objects at all, it just knows where in memory the various parts of it are, and encodes that directly into the code.
Performance Results With JIT
With the regular expression matcher translated to C and with a generated JIT, the regular expression performance increases significantly. Our running example can match 16'500'000 chars/s, which is more than six times faster than the re module. This is not an entirely fair comparison, because the re module can give more information than just "matches" or "doesn't match", but it's still interesting to see. A more relevant comparison is that between the program with and without a JIT: Generating a JIT speeds the matcher up by more than 20 times.
Conclusion
So, what have we actually won? We translated the relatively simple and very slow regular expression matching algorithm from the last post to C and were thus able to speed it up significantly. The real win is gained by also generating a JIT for the matcher, which can be regarded as a simple interpreter. The resulting matcher is rather fast.
The lesson from these posts is not that you can or should write a practical and general regular expression module in this way – indeed, enhancing the algorithm to support more features of the re module would be a lot of work and it is also unclear what the speed results for more realistic regular expressions would be. However, it makes for a great case study of the JIT generator. It was relatively straightforward to generate a JIT for the regex matcher, and the speed results were great (Admittedly I know rather a lot about PyPy's JIT though). This approach is generalizable to many programs that are sufficiently "interpreter-like" (whatever that exactly means).
All the results that appeared at various points in this blog post can be seen here:
| Implementation | chars/s | speedup over pure Python |
| Pure Python code | 12'200 | 1 |
| Python re module | 2'500'000 | 205 |
| Google's re2 implementation | 550'000 | 45 |
| RPython implementation translated to C | 720'000 | 59 |
| C++ implementation | 750'000 | 61 |
| Java implementation | 1'920'000 | 157 |
| RPython implementation with JIT | 16'500'000 | 1352 |
Sources
All the source code can be found in my Subversion user directory on Codespeak.
Edit:
Armin is right (see first comment). I fixed the problem.
Warning: the first example is wrong: there should be no code executed between can_enter_jit() and jit_merge_point(). In this case, there is the exit condition of the loop. It needs to be rewritten as a "while True:" loop with a "break" just before can_enter_jit().
What happens if you don't replace and and or?
Without those changes, the modifications for JIT really are prety small --
mostly just some annotations in the main loop and at toplevel for each
class. With those changes, though, you need to potentially check the entire
codebase of your interpreter.
Pretty fun performance results, though.
@Nelson: If you don't change the "and" and "or" you get a lot of assembler code generated, and it's not particularly fast.
Note that this "and" and "or" business is quite specific to this particular example. Usually you can work more incrementally by generating a JIT, then looking at the produced assembler and then doing some small changes in the interpreter to improve parts of it. Each such change is usually localized to one part of the interpreter improves the performance of some language feature.
This example is not really large enough to show this way of working, though :-). Maybe at some point I should write a walk-through for some interpreter.
Would it be possible to create a pypy or cpython extension module this way?
Could you post your 'test runner' code? I'm running some tests (with your) code and getting drastically different numbers...
@jabapyth: there is no test runner code. I am simply running something like
genrandom 20 1000000 | time regex-c
What performance results are you getting? Are you sure that you translated jitregex.py with -Ojit? Otherwise the JIT is not put into the executable.
boost::regex is not mentioned. It's got both recursive and non-recursive implementations. And it is the base of the standard C++ TR1 regex. Would be interesting to stack it up against other results because it is
We can't possibly include all regex engines (even if we would like to). However, sources are out there and you can always rerun those benchmarks and see how it compares :-)
Cheers,
fijal
I'm not able to access the code on codespeak.net. Has the code been moved to some other place?
PyPy in Google's Summer of Code 2010
Good news everyone.
This year, thanks to google generosity and PSF support, we got two and a half of students for PyPy's summer of code. We didn't cut any students, but one of the projects is a joint project of PyPy and numpy. Hereby I present descriptions, in my own words with my own opinions and in arbitrary order. For more details please follow links to particular blogs.
Jason Creighton: 64bit JIT backend for PyPy
Intel 64bit (and I mean x86_64) compatibility for JIT has been one of the top requested features (along with GIL removal). While GIL removal is not really an easy task, having our JIT emit 64bit assembler is sort of easy, thanks to our JIT backend abstraction. It will likely be faster, thanks to abundance of registers.
Bartosz Skowron: Fast ctypes for PyPy
Historically weak point of PyPy was compatibility with extension modules. We have progressed quite a bit in recent years, first introducing ctypes for pypy then progressing towards CPython extension modules. However, ctypes is well known to be slow (and it's even slower on PyPy) and writing CPython extension modules is ugly, and it's going to be only with compatibility layer that'll keep this slow. What happens if we try to employ JIT technology to ctypes? Maybe we can compile calls to C code from Python as a direct calls in compiled assembler? Why not?
This project will look how the JIT technology can be employed to do some sort of FFI. There is no guarantee we'll get super-fast ctypes as a result, but it's good to see progress in that area.
Dan Roberts: Numpy in PyPy
This is a joint project of numpy and PyPy. The main objective is to bring numpy to PyPy, possibly fast. The official mentor for this project is Stefan van der Walt from numpy community. During initial meeting it was agreed that probably the best way to go would be to support original numpy with CPython extension compatibility and then provide a minimal native numpy framework for pypy. The former would retain full compatibility, while the latter would have JIT integration, with line of our previous numeric experiments. There would be an explicit interface from converting one array to another for convinience.
Overall, I'm very happy to see so much support for PyPy from SoC. I hope all three proposals will be successful!
Cheers,
fijal & pypy team.
Some really nice stuff in there, very interested in the potential for JIT + numpy, keep up the good work!
Cool projects. Two of them live as PyPy branches:
https://codespeak.net/viewvc/pypy/branch/x86-64-jit-backend/
https://codespeak.net/viewvc/pypy/branch/fast-ctypes/
Where can we follow the NumPy work? :)
when will pypy catch up with python 3.1? will it happen during the python language moratorium (pep 3003)?
An Efficient and Elegant Regular Expression Matcher in Python
Two weeks ago, I was at the Workshop Programmiersprachen und Rechenkonzepte, a yearly meeting of German programming language researchers. At the workshop, Frank Huch and Sebastian Fischer gave a really excellent talk about an elegant regular expression matcher written in Haskell. One design goal of the matcher was to run in time linear to the length of the input string (i.e. without backtracking) and linear in the size of the regular expression. The memory use should also only be linear in the regular expression.
During the workshop, some of the Haskell people and me then implemented the algorithm in (R)Python. Involved were Frank, Sebastian, Baltasar Trancón y Widemann, Bernd Braßel and Fabian Reck.
In this blog post I want to describe this implementation and show the code of it, because it is quite simple. In a later post I will show what optimizations PyPy can perform on this matcher and also do some benchmarks.
A Note on terminology: In the rest of the post "regular expression" is meant in the Computer Science sense, not in the POSIX sense. Most importantly, that means that back-references are not allowed.
Another note: This algorithm could not be used to implement PyPy's re module! So it won't help to speed up this currently rather slow implementation.
Implementing Regular Expression Matchers
There are two typical approaches to implement regular expression. A naive one is to use a back-tracking implementation, which can lead to exponential matching times given a sufficiently evil regular expression.
The other, more complex one, is to transform the regular expression into a non-deterministic finite automaton (NFA) and then transform the NFA into a deterministic finite automaton (DFA). A DFA can be used to efficiently match a string, the problem of this approach is that turning an NFA into a DFA can lead to exponentially large automatons.
Given this problem of potential memory explosion, a more sophisticated approach to matching is to not construct the DFA fully, but instead use the NFA for matching. This requires some care, because it is necessary to keep track of which set of states the automaton is in (it is not just one state, because the automaton is non-deterministic).
The algorithm described here is essentially equivalent to this approach, however it does not need an intermediate NFA and represents a state of a corresponding DFA as marked regular expression (represented as a tree of nodes). For many details about an alternative approach to implement regular expressions efficiently, see Russ Cox excellent article collection.
The Algorithm
In the algorithm the regular expression is represented as a tree of nodes. The leaves of the nodes can match exactly one character (or the epsilon node, which matches the empty string). The inner nodes of the tree combine other nodes in various ways, like alternative, sequence or repetition. Every node in the tree can potentially have a mark. The meaning of the mark is that a node is marked, if that sub-expression matches the string seen so far.
The basic approach of the algorithm is that for every character of the input string the regular expression tree is walked and a number of the nodes in the regular expression are marked. At the end of the string, if the top-level node is marked, the string matches, otherwise it does not. At the beginning of the string, one mark gets shifted into the regular expression from the top, and then the marks that are in the regex already are shifted around for every additional character.
Let's start looking at some code, and an example to make this clearer. The base class of all regular expression nodes is this:
class Regex(object):
def __init__(self, empty):
# empty denotes whether the regular expression
# can match the empty string
self.empty = empty
# mark that is shifted through the regex
self.marked = False
def reset(self):
""" reset all marks in the regular expression """
self.marked = False
def shift(self, c, mark):
""" shift the mark from left to right, matching character c."""
# _shift is implemented in the concrete classes
marked = self._shift(c, mark)
self.marked = marked
return marked
The match function which checks whether a string matches a regex is:
def match(re, s):
if not s:
return re.empty
# shift a mark in from the left
result = re.shift(s[0], True)
for c in s[1:]:
# shift the internal marks around
result = re.shift(c, False)
re.reset()
return result
The most important subclass of Regex is Char, which matches one concrete character:
class Char(Regex):
def __init__(self, c):
Regex.__init__(self, False)
self.c = c
def _shift(self, c, mark):
return mark and c == self.c
Shifting the mark through Char is easy: a Char instance retains a mark that is shifted in when the current character is the same as that in the instance.
Another easy case is that of the empty regular expression Epsilon:
class Epsilon(Regex):
def __init__(self):
Regex.__init__(self, empty=True)
def _shift(self, c, mark):
return False
Epsilons never get a mark, but they can match the empty string.
Alternative
Now the more interesting cases remain. First we define an abstract base class Binary for the case of composite regular expressions with two children, and then the first subclass Alternative which matches if either of two regular expressions matches the string (usual regular expressions syntax a|b).
class Binary(Regex):
def __init__(self, left, right, empty):
Regex.__init__(self, empty)
self.left = left
self.right = right
def reset(self):
self.left.reset()
self.right.reset()
Regex.reset(self)
class Alternative(Binary):
def __init__(self, left, right):
empty = left.empty or right.empty
Binary.__init__(self, left, right, empty)
def _shift(self, c, mark):
marked_left = self.left.shift(c, mark)
marked_right = self.right.shift(c, mark)
return marked_left or marked_right
An Alternative can match the empty string, if either of its children can. Similarly, shifting a mark into an Alternative shifts it into both its children. If either of the children are marked afterwards, the Alternative is marked too.
As an example, consider the regular expression a|b|c, which would be represented by the objects Alternative(Alternative(Char('a'), Char('b')), Char('c')). Matching the string "a" would lead to the following marks in the regular expression objects (green nodes are marked, white ones are unmarked):
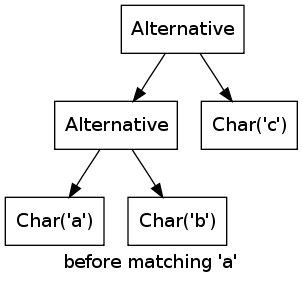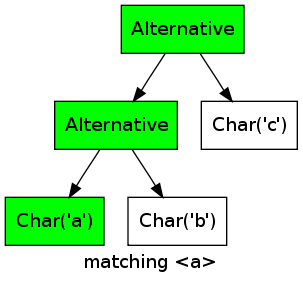
At the start of the process, no node is marked. Then the first char is matched, which adds a mark to the Char('a') node, and the mark will propagate up the two Alternative nodes.
Repetition
The two remaining classes are slightly trickier. Repetition is used to match a regular expression any number of times (usual regular expressions syntax a*):
class Repetition(Regex):
def __init__(self, re):
Regex.__init__(self, True)
self.re = re
def _shift(self, c, mark):
return self.re.shift(c, mark or self.marked)
def reset(self):
self.re.reset()
Regex.reset(self)
A Repetition can always match the empty string. The mark is shifted into the child, but if the Repetition is already marked, this will be shifted into the child as well, because the Repetition could match a second time.
As an example, consider the regular expression (a|b|c)* matching the string abcbac:
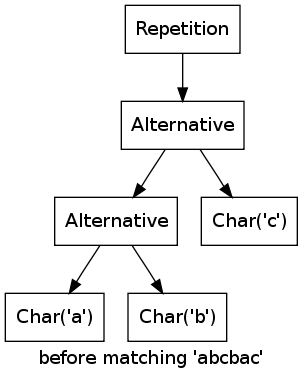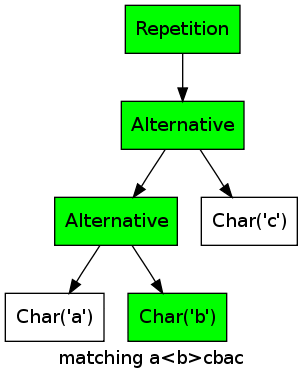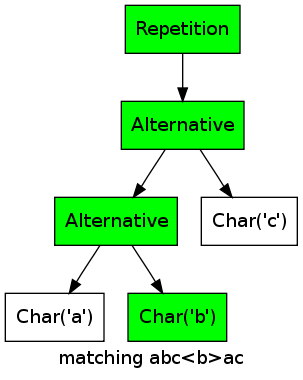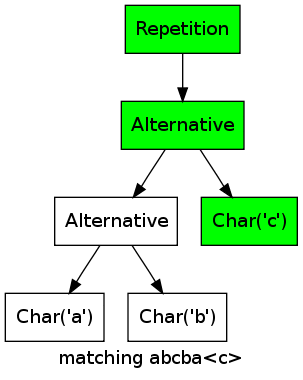
For every character, one of the alternatives matches, thus the repetition matches as well.
Sequence
The only missing class is that for sequences of expressions, Sequence (usual regular expressions syntax ab):
class Sequence(Binary):
def __init__(self, left, right):
empty = left.empty and right.empty
Binary.__init__(self, left, right, empty)
def _shift(self, c, mark):
old_marked_left = self.left.marked
marked_left = self.left.shift(c, mark)
marked_right = self.right.shift(
c, old_marked_left or (mark and self.left.empty))
return (marked_left and self.right.empty) or marked_right
A Sequence can be empty only if both its children are empty. The mark handling is a bit delicate. If a mark is shifted in, it will be shifted to the left child regular expression. If that left child is already marked before the shift, that mark is shifted to the right child. If the left child can match the empty string, the right child gets the mark shifted in as well.
The whole sequence matches (i.e. is marked), if the left child is marked after the shift and if the right child can match the empty string, or if the right child is marked.
Consider the regular expression abc matching the string abcd. For the first three characters, the marks wander from left to right, when the d is reached, the matching fails.
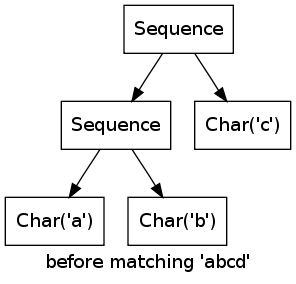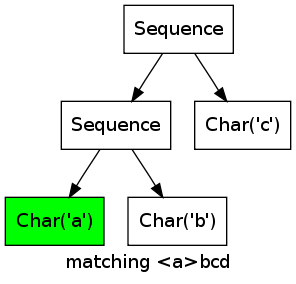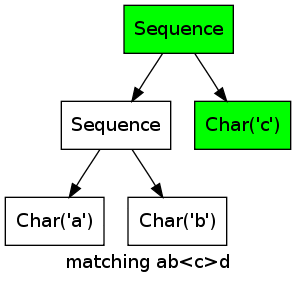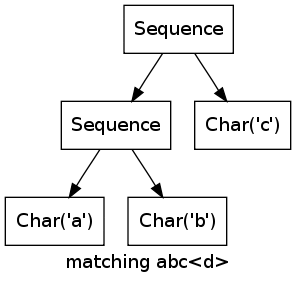
More Complex Example
As a more complex example, consider the expression ((abc)*|(abcd))(d|e) matching the string abcabcabcd.
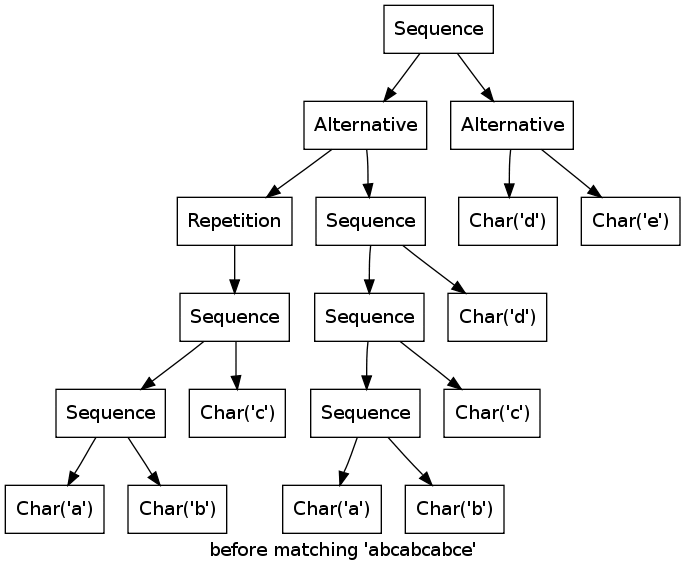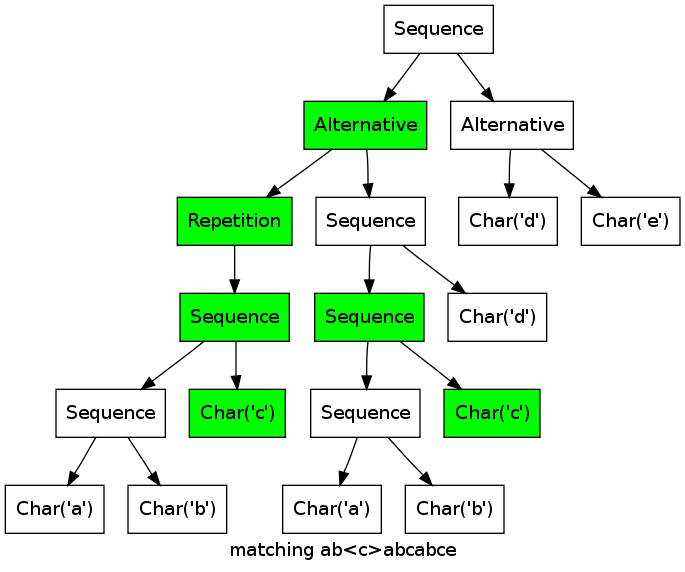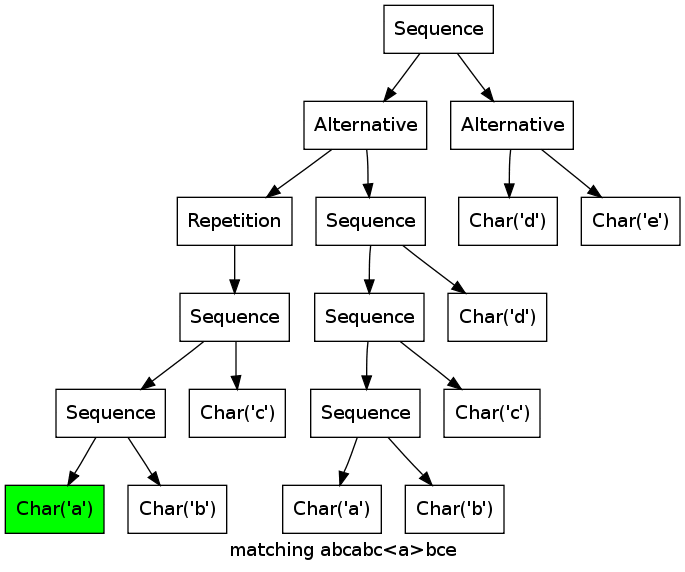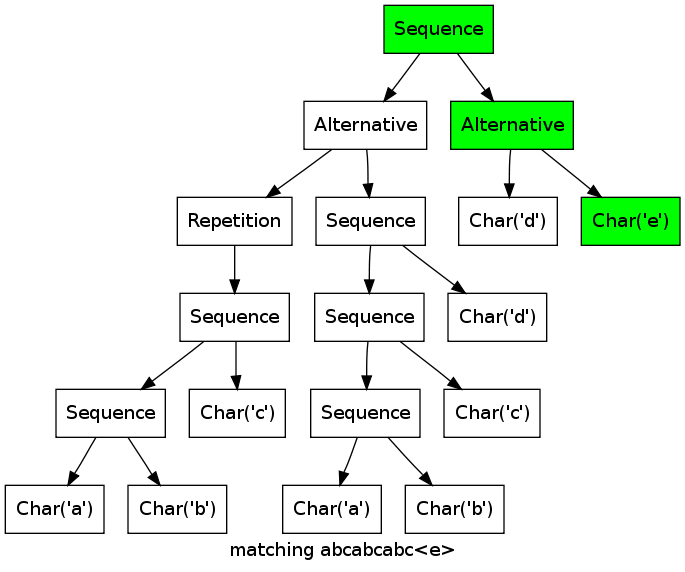
Note how the two branches of the first alternative match the first abc in parallel, until it becomes clear that only the left alternative (abc)* can work.
Complexity
The match function above loops over the entire string without going back and forth. Each iteration goes over the whole tree every time. Thus the complexity of the algorithm is O(m*n) where m is the size of the regular expression and n is the length of the string.
Summary & Outlook
So, what have we achieved now? The code shown here can match regular expressions with the desired complexity. It is also not much code. By itself, the Python code shown above is not terribly efficient. In the next post I will show how the JIT generator can be used to make the simple matcher shown above really fast.
Have you seen Russ Cox's series of articles about regular expressions?
Google Chrome's regexp library is also interesting.
Google appears to have put a lot of research in efficient regexp algorithms while paying attention to backwards-compatibility concerns, as existing applications often rely on backtracking.
Limited backreferences can be integrated within this pattern matching scheme. General backreferences are only possible with backtracking but unless you want to solve NP complete problems using POSIX style regexps they might not be necessary.
Marius: The Russ Cox site is linked from the article :-).
Kay: Thanks for the link, will check it out.
I do not use regular expressions very heavily and am very new to pypy in general (1.2 works pretty good for me on my pure python code). From this article I don't see a full explaination why this basic algorithm couldn't be used for pypy. Is it primarily due to concerns about backward compatiblity or something more interesting? I am looking forward to the article to come about applying the JIT.
This is just beautiful, I hope some version of this will be available for PyPy users: sandboxing + non-pathological REs sounds like a nice combo.
Though these regexes can't be used as a drop-in replacement for the re module, if there were strikingly faster it might be worth having them as an alternative. The backtracking features are so seldom required that a faster, non-backtracking algorithm might prove popular with people who worry about matching speed.
It would be fun to read an article where you take the real Python regexes and apply PyPy's JIT code generation to them, i.e. when you call re.compile(...), you'd get native code out of it, specialized for the regex being compiled. After all, haven't you used the JIT on "toy" languages before? Regexes are a "toy" language, albeit a useful one..
Anonymous2: Yes, but PyPy's current implementation of the re module is a bit of a mess, and not really fast. It's rather unclear how easy/possible it would be to generate a good JIT for it.
Instead of a "special" interpreter for REs in RPython, and a JIT for it, what about "compiling" REs to Python bytecode, and letting the existing PyPy JIT trace and compile them if they end up being used often enough? This is probably slower in the case of lots of throwaway REs that are used once, but when a few REs are used repeatedly it ought to work.
Running wxPython on top of pypy
Hello,
These last three weeks we have been busy working on the cpyext subsystem, which allows pypy to execute extension modules written with the Python C API.
Today we hacked enough to have wxPython compile, and run its wonderful demo.
This:
 cannot be distinguished from the same run with a
standard python interpreter, but this:
cannot be distinguished from the same run with a
standard python interpreter, but this:
 shows an exception that
CPython never produces.
shows an exception that
CPython never produces.
wxPython is a big extension module: it has more than 500 classes and 7500 functions, most of the code is automatically generated by swig. It uses advanced techniques, like "Original Object Return" and cross-platform polymorphism, that effectively allows the developer to seamlessly subclass C++ objects in Python and write GUI applications efficiently.
The demo application runs reasonably fast, it feels slower than with CPython, but I did not activate the JIT option of pypy. It still crashes in some places (the demo is very comprehensive and covers all the aspects of wxPython), and threads are expected to not work at the moment.
We had to modify a little the code of wxPython, mainly because it often stores borrowed references into C++ objects. This does not work well in pypy, where all other counted references can disappear, and allows the address of the object to change. The solution is to use weak references instead. The patch is here, it will eventually be merged into the upstream wxPython version.
This first real test proves that CPython extensions can be migrated to pypy without much pain. It also points some places which can be improved, like better diagnostics in crashes, better support of distutils...
Amaury Forgeot d'Arc
Nice! Do you have any plans for making Mac nightlies with this available? I'd love to try out PyPy, but the one time I tried bootstrapping, it used all available memory. After I had let it run overnight but it didn't finish, I killed it…
This is very good news.
Finishing wxPython and the JIT is probably all that's needed to make PyPy a **great** alternative to CPython. (but I guess you figured that already)
Thanks!
Sweet ! I wonder if pycairo and pygtk... at the moment I don't know if it's cairo or python slowing down my app (I have an idea it's both, but running it in pypy does seem attractive).
Are there docs for how to compile extensions somewhere? I had a quick look, but couldn't find them.
this is a major accomplishment in terms of usability, many people use Python extension modules, way to go. (and next steps, PIL).
PIL also works with PyPy. I've only tried basic tests though (like gif->png conversion)
@illume: you have to compile pypy with the option "--withmod-cpyext", then it should be enough to run "/path/to/pypy-c setup.py build"
Well done! The Italian Python Community has an article on this (here, in Italian)
Just awesome.
Finding gelato hopefully won't be a problem at next year's EuroPython. ;-)